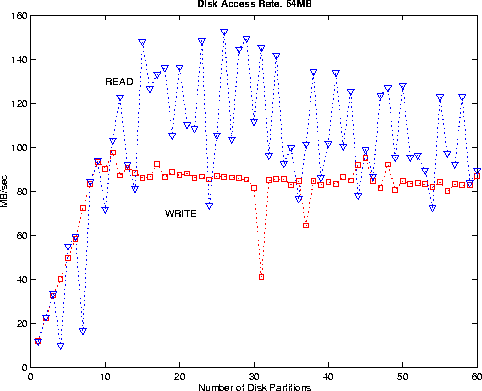
Figure 1. I/O Rates for a single file access by a single processor. As the file is striped over increasing number of disk partitions, the I/O rates reach to about 90 MB/s for writing and about 100 MB/s for reading.
We have investigated parallel input/output on the CRAY T3E. Currently MPI-IO is not available on T3E. However, CRAY provides a global file feature within the Cray FFIO file systems, with either record number (for direct access files) or setpos (set file position, similar to fseek in C, in sequential access files) to coordinate the collective I/O operations. We studied various aspects of these parallel I/O approaches, and compared them to the single-processor I/O plus message passing approach, that most current real-life applications use. Our main conclusions are
(1) Single-Processor I/O + MPI. It offers reasonable high I/O rates (60-80 MB/s), and codes are portable; file transferable to other computer platforms. But it requires explicit programming of collective operations among multiple PEs, and memory limitations on single processor also require additional coding.
(2) Cray Global file with direct access file and record numbers. It offers higher rates (up to 100 MB/s) and simpler API; but the existence of explicit record length made it less flexible.
(3) Cray Global file with sequential file and set position. It offer low I/O rates (~10 MB/s), but is more flexible than fixed record length files, this good for serving relatively small (< 1MB) individual data sets or parameters. Both (2) and (3) are not CRAY specific, thus non-portable. But they handle large data sets, without additional coding.
(4) An mixed approach combining Cray Global file with direct access file and message passing. It is recommanded for parallel I/O on T3E. It retains the high I/O rates, can handle large data sets, and provide enough flexibility (for example, can easily read in a matrix for a 2D distribution).
(5) Each processor accesses a separate file. This approach offers high I/O rates (up to 140MB/s), and is easy to handle. This is good for out-of-core solution type of method which require a large o number of disk to hold temporary files.
After examination of these basic I/O approaches, we discuss effective I/O strategies for typical user I/O modes in many scientific/engineering applications:
1. Introduction
While CPU processing speed increases dramatically in recently years, the accessing speed for input/output data on secondary storage such as disks have improved relatively little. The situation is made worse because application problem sizes on MPP are becoming bigger and bigger, and so are the I/O requirements.
Many application codes are developed when the problem size is modest; the design of I/O were not paid full attention. As the problem sizes grow in accordance with the computing power of MPPs, I/O part in many cases become the bottleneck! A 5% I/O time for an application on a sequential machine limits the maximum speedup of 20 on any MPPs according to Amdahl's law.
There are two main issues regarding input/output operations on distributed- memory multi-processor computers like the Cray T3E. For many applications, the access speed is of primary concern. Although the aggregate transfer rate of disk write/read can achieve 100MB/sec level under optimal conditions, requiring disk-striping, very large data sizes (64MB or larger), low I/O load, etc., the achieved I/O rate on many practical applications are typically quite low.
Another issue is the application programming interface (API) for the distributed-memory parallel file system. The API has been extensive investigated by the Scalable I/O Initiative[1], MPI-IO[2] and other projects. The generic API standards are proposed, but not implemented yet at least for T3E.
Further complicating the I/O issue on T3E is the "assign" mechanism in controlling disk striping, data buffering. By default, files are created on only one disk partition, without disk-striping, so the maximum transfer rates one can achieve is about 10MB/s. Figure 1 shows how the transfer rates increase when the file is striped over more disk partitions. Chosing the right data buffering to achieve high I/O rates is also fairly tricky. Generally on single channel I/O, the asynchronous "assign -F bufa" gives the best rates. (Note that unless stated otherwise, I/O transfer rate measured here are effective rates, i.e., the timing includes file open and close times. This is because I/O system on T3E uses extensive data caching and user-space buffering, time for file open and close are non-negligible. Simple write/read rates could often be confusingly higher and are not objective measure of I/O efficiency.) Pre-allocation of disk space can prevent certain problems like not-enough space when a job generate a large data file. It can also reconfigure the disks if they too fragmented. This will increase I/O speed.
Figure 1. I/O Rates for a single file access by a single
processor. As the file is striped over increasing
number of disk partitions, the I/O rates reach to about 90 MB/s
for writing and about 100 MB/s for reading.
For these reasons, we have carried out a systematic study of the available I/O system on T3E, understand the different choices, and measure many relevant I/O characteristics. Based on these studies, effective strategies are investigate and suggested for user I/O access patterns identified over a large range of applications.
2. Parallel I/O approaches on CRAY T3E
2.A. Single-processor I/O + MPI Approach
A simple approach is to use the standard UNIX I/O interface with only one processor accessing disk files and communicating with all the rest processors using message passing. The codes written in this way is portable to all UNIX systems due to the standard UNIX I/O interface. Furthermore, this approach scales reasonably well to large number of processors because inter-node communication is typically much faster than the I/O speed, especially in T3E. See Figure 2 .
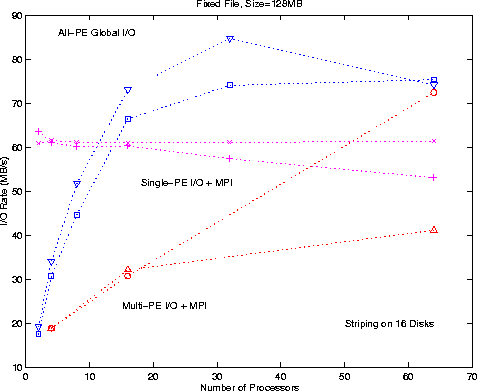
Figure 2. I/O Rates for three parallel I/O approaches.
Blue curves for ALL-PE Global I/O with direct access, without MPI. Sec.2.C.
Magenta curves Single-PE I/O + MPI, Sec.2.A.
Red curves for mix Multi-PE I/O + MPI where a fraction of PEs access the file
with direct access. Sec.2.D. The single file size is 128MB. Striped over 16
disk partitions.
Thirdly, the input and output data files are identical for all sequential processing environments, independent of how many processors will access them. If one setups files specific to 32 PEs, they won't work on 16 or 64 PEs. This also for analyzing simulation results on a different platform, say SGI graphics workstation. (This single sequential file transferable to all other UNIX environment is impity is important for practical effective use of MPP systems, and will be emphasized in the follow.)
For these three reasons, portability, scalability, and file transferability, this approach works well for many MPP applications and is widely adopted in practice.
However, this conceptually-simple approach requires lengthy implementations. For every single I/O operations, one has to write codes to pass the data between IO-PE and compute PEs, resulting in large amount of extra redundancy and complexity in programming and diagnostics. Ease of programming is lost in this approach.
Another problem with the simple approach is that the I/O operation speed is limited by the single processor I/O speed. In many MPP environments, IO operations can proceed on multiple channels through multiple processors, greatly increase the data transfers. Figure 3 shows the aggregate transfer rate as the number of independent files increase with number of processors. On 64 PEs, we can achieve about 140MB/s.
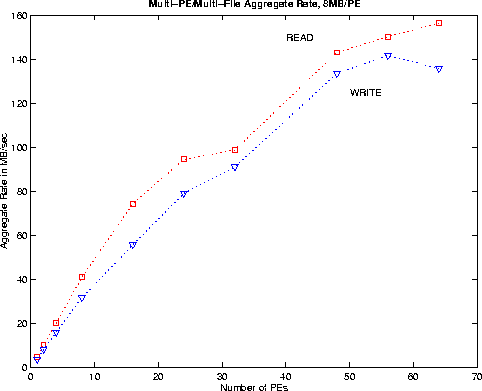
Figure 3. Each PE read/write to a separate 8MB file. All
PEs are doing this simultaneously and independently. The I/O
rate is the aggregate rate, i.e., simply adding up the rates for all
PEs.
Yet another problem with the simple approach is memory limitations on the IO-PE, which uses its local memory in buffering stage. (For example, the IO-PE receives from compute PEs all the matrix blocks of a global dense matrix and reshuffles data to correct order regarding to the two index, before writing out to disk file.) However, most applications have data configurations larger than the local memory on the IO-PE, especially for memory-bounded applications.
The memory requirement could be relaxed in the following ways: (a) by doing a portion of the data array at a time, and repeat as necessary; (b) by using two processors accessing the same data file, but different portions of the file; then each processor distribute data to their corresponding group; (c) by split the data file into two separate files and let two processors access them independently. Method (a) is the portable way. Method (b) could presumably speed up the I/O by overlapping the redistribution of first half with the I/O on second half. Method (c) presumably can speedup the I/O access time because two independent processors are reading two separate data files. More on this in Sec.2.B.
2.B. Multi-PE Multi-file approach
Several PEs do I/O simultaneously, each PE accesses a separate file. No coordinations between different files exist. (This is most apparent on IBM SP where one may attach a local disk to each processor.) This works for the out-of-core problems for which we need large amount of temporary files, This approach is a simple extension of the single-PE approach. It relaxes the memory-limitation offered by a single PE; it also speedups the I/O rate by using more I/O channels ( Figure 2 ).
This approach can also handle a single multi-dimensional data array, or problems which have inherent natural subdivisions. Consider a global matrix distributed on a 2D array of PEs, each PE contains a rectangle subblocks of the matrix. Imagine a row of processors form a MPI process group. Then the matrix subblocks on these processors can be gathered into the processor with rank 0 in this row group. The aggregate subblock on the rank-0 processor then contains several complete columns of the global matrix, therefore corresponding to a contiguous portion in the data file (assuming column major storage as in Fortran). Thus the original data file containing the global matrix can be split into several files, each containing the complete matrix columns for a particular processor row, ready to be accessed by the rank-0 processor. (Note that MPI_Gather/MPI_Scatter cannot be used directly to gather/scatter to/from the rank-0 processor because the dimension to be split in the aggregate subblock refers to the fast running index, not the slow running index. However, they can be used after a local data reshuffle[3].)
The big drawback of this approach is that one has to manipulate many files which would have been a single data file. However, when dealing with very large data configuration files, sometimes it is necessary to break the single huge file into several smaller files.
2.C. Cray FFIO with global file
In the default Unix interface, simultaneous write to the same single file from multiple processes are not well defined. The In Cray FFIO[4] on T3E, a global file access mode (specified by "assign -F global") is provided, which coordinate between different processors, both in file position and in data buffering.
There are two different ways for this.
Direct access mode
For direct access files, one use the record number for different data segments. In Figure 3 the I/O rates for direct access with global file are shown. Here the size on each PE is fixed to 32MB, therefore the global file sizes increase as the number of PEs increases. Clearly, with direct access one can achieve about 100MB/s sustained rates.
Although the global file feature is CRAY specific, this mode with direct access with record number is fairly easy to use and confirms to Fortran standards. The drawback is that the file is written with fixed record length for every records and thus implicitly requires that every I/O transaction size must be that fixed record length. This is inconvenient for many applications where it is desirable that the data files are written in a way independent of how many processors the application uses (transferable feature mentioned in section 4).
Sequential access mode
For sequential access files, one can use setpos (set file position) and getpos (get file position) to deal with separate data segments within a single file.
Sequential access with setpos/getpos is more flexible on I/O sizes from different PEs. But the I/O performance is only at 10MB/s range (see Figure 3 ), far below that of direct access with record number.
2.D. A mixed approach combining multi-PE I/O with MPI
This is similar to the multi-PE multi-file approach of sec.2.B. except that the multiple files are replaced by the single global file accessed by multiple PEs using Cray global file. As the discussion of the 2D matrix case there, the rank-0 processors access the file, and no file split is necessary, therefore maintaining the highly desirable single file structure. The achieved I/O rates are quite high (see Figure 4 ).


 Last figure
Last figure

Figure 4. I/O rates for all PEs accessing a single file using
CRAY global file feature. The direct access with record number
reaches about 550MB/s on 64 PEs, whereas the sequential
access with set file position reaches about 750MB/s range. Each PE
has a fixed 32MB portion of the file while the global file size
increases accordingly as number of PEs increases. File is
striped over 39 disk partitions.
Although only a fraction of total allocated processors actually ever access the file, all must participate in open/close the file due to the CRAY FFIO global mode requirements. This causes complications in some applications, for example in the Camille climate model codes[5] where a master PE is used. Synchronization of all PEs with the master PE is not always possible or advisable.
3. Parallel I/O for multi-dimensional arrays
3.A. 1D Arrays.
Since all the I/O interfaces are 1D array oriented, all the aboved mentioned approach can be used for 1D array. In particular, only a single MPI_Scatter (or MPI_Scatterv for varying sizes on each processor) is invoked in reading in either Single-PE I/O + MPI or Multi-PE I/O + MPI approaches. Writing follows the reversed order. 1D distribution can be easily handled easily and efficiently.
3.B. 2D Arrays
An example is a 2D matrix distributed on a 2D processor array by dividing both i and j dimensions. The 2D distribution are more complicated due to the fact that data in matrix subblock are not contiguous in the original global matrix data array and can not be extracted using a single memory copy. If the global array is not too large and can fit to local memory, the single-PE + MPI approach can be used. But in many applications, data is too large; we recommand the mixed approach using Multi-PE I/O + MPI discussed in sec.2.D above.
3.C. Multi-dimensional arrays
One can extend the mixed Multi-PE I/O + MPI approach to handle I/O for 3D arrays on 3D distributions. But more often, applications with high dimensional data arrays use lower dimension domain decomposition, for a variety of practical reasons. For example, a 3D array of a 3DFFT problem uses 1D domain decomposition[3]. In this case, the data array is split in the dimension with the the slowest running index, the k index in Fortran arrays U(i,j,k). This is dictated by how the 3D data is mapped into linear storage in memory in the language. All I/O approaches for 1D array (sec.3.A) can be used here. Similarly, the same 3D array could use 2D domain decomposition, and I/O approaches for 2D arrays can be adopted accordingly.
4. User I/O Patterns
Here common I/O access patterns from application programmer's perspective are gathered from many applications that I had been involved and from other people's applications. (See [6] for a collection of recent papers on I/O in parallel applications.) The effective strategies to handle with them are discussed using the basic I/O approaches discussed in sections 2 and 3.
4.A. Reading parameters. Reading parameters from a single parameter/ control file. Best way is use single-PE approach. Let the master-PE read and broadcast to all other PEs.
4.B. Log file. Log files are used for collecting simulation history and diagnostic/monitoring information. Typically write to standout (unit=6) or errorout (unit=0). Ordering of messages from each PE is not important. Use formatted data. No more than 80 characters each line.
4.C. Temporary files. Files generated during the computation mostly due to insufficient memory space on each PE (out-of-core problems). If total PEs are not too large ( <= 64), let each PE open/read/write its own private file. Otherwise, use multi-PE I/O + MPI approach.
4.D. Multiple event simulations. Application use Single Program Multiple Data (SPMD) paradigm. But each simulated an independent events, distinguished by different input parameters/data in a single input file. Inputs to a PE may have different data type, length, etc. Use single-PE I/O + send/receive with the input file. Each PE writes to a separate output file.
4.E. Linked-list. This is best done in Single-PE I/O approach, because: (1) nodes (structures, derived-types) could be allocated dis-contiguously in memory; (2) end-point (null) needs to be modified to link lists from different PEs. Similar to Sec.4.D.
4.F. Multiple Data Configurations. The same data field, such as 3D wind velocity array, should be a single file following the natural sequential order, thus is file-transferable. Use the approaches for multi-dimensional array in sec.4. Different data fields, temperature field, should in general stored in separate file, from the wind velocity file.
4.G. Checkpointing. Needs two file: (1) parameter file, including all current parameters and current random number generators if any. (2) configuration file (or files). Different data fields maybe use separate files, as in sec.4.F.
4.H. Filenames and character strings. I/O for file names and character strings are best done in formatted mode, i.e., the ASCII file, so both Fortran and C codes can read it on any computer platforms. They can be easily pass around using MPI_Character data type. This avoids the inherent non-portable nature of character strings in Fortran (implementation dependent).
Acknowledgement. This work is supported by the U.S. Department of Energy under contract number DE-AC03- 76SF00098. This research also uses resources of the National Energy Research Scientific Computing Center, supported by the DOE Office of Energy Research. I thank Mike Stewart, Steve Caruso, and Steve Luzmoor for providing some initial examples.
References