



In a distributed memory parallel environment, many applications rely on a serial I/O strategy, where the global array is gathered on a single MPI process and then written out to a file. I/O performance with this approach is largely limited by single process' I/O bandwidth. Even when parallel I/O is used, satisfactory parallel scaling is not always observed. It is because in many applications fields are not necessarily in a most favorable parallel decomposition for I/O. The best I/O rates are obtained when a field is decomposed with respect to the array's last dimension (referred to here as ``Z'').
Another situation often encountered in many applications is that a field in CPU resident memory is in one index order but must be stored in a disk file in another order. Changing index orders can complicate a parallel I/O implementation and slow down I/O.
ZioLib facilitates efficient parallel I/O for arrays in such situations. In case of a write, ZioLib remaps a distributed field into a Z-decomposition on a subset of processes (which will be called the I/O staging processes) and from there launches a write to a disk file in parallel (see Figure 1). In this Z-decomposition, the data layout of the remapped array on the staging processes' memory is the same as on disk, thus only block data transfer occurs during parallel I/O, achieving maximum efficiency. In case of a read the steps are reversed to build the required distributed arrays on the computational processes.
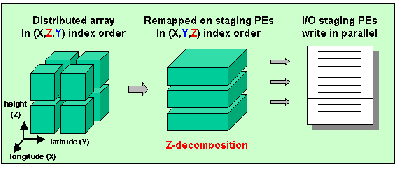
Figure 1: Writing the global field of distributed array a(X,Z,Y)
to a disk file in (X,Y,Z) index order using
three I/O staging processes.
Please see more information at http://www.nersc.gov/research/SCG/acpi/ZioLib/.