Adaptively Applying Data-driven Execution Mode to
Remove I/O Bottleneck for Data-intensive Computing
The
increasingly popular multi-core/many-core technique is effective for accelerating
programs' executions only when sufficient parallelism is maintained. For
data-intensive programs, the increased parallelism in the execution can
severely compromise their I/O efficiency. When a sequential program is
parallelized, not only computations but also the I/O operations associated with
them can be distributed among multiple processes. Because the execution order
of the processes is usually determined by the scheduler at runtime, the
relative progress of each process is nondeterministic and the order in which
the processes issue their I/O requests is accordingly nondeterministic.
As
the layers of the I/O stack responsible for serving I/O requests, including
caching, prefetching, and I/O scheduling, all rely on predictability on I/O
request pattern, such I/O non-determinism can have three effects compromising
I/O efficiency. (1) The opportunities for reusing data in the buffer cache by
different processes can be missed, leading to weakened temporal locality,
because existing process scheduling does not consider the buffer cache. (2) As
individual processes independently generate prefetch requests, it would be hard
to aggregate these requests into a long sequential I/O stream, which is
preferred by the storage system. (3) The I/O scheduler is difficult to exploit
spatial locality among requests from different processes to form large requests
for higher I/O efficiency. The nondeterministic issuance and uncoordinated
service of requests can result in serious I/O bottleneck. For the hard disk, small
random access can lead to an I/O performance degradation of one order of
magnitude. For the solid-state disk, random writes can substantially increase
garbage collection cost and reduce its throughput.
In
the project we built facilities to harmonize or streamline the service of I/O
requests from different processes of a parallel program. There is a major
distinction between the facilities and conventional techniques for improving
I/O performance. Conventional techniques, such as improved I/O schedulers,
caching, and prefetching policies, only optimize the service of I/O requests.
In contrast, the proposed facilities manage issuance of I/O requests through
I/O-aware process scheduling and service of these requests with improved
locality in a coordinated fashion for I/O-intensive multithreaded and MPI
programs. When the I/O bottleneck is detected for a parallel program, the
execution of the program and service of its I/O requests will deviate from its
regular statement-driven mode to the data-driven mode. In the data-driven mode,
all processes of a program collectively disclose their future I/O data needs
through pre-execution for reads and through write-back for writes, and wait for
the data to be efficiently prefetched into the cache or be flushed into the
storage to proceed. So that I/O efficiency and data availability can take
priority in the process scheduling. The facilities includes iHarmonizer,
a runtime for improving I/O performance of multi-threaded programs, and DualPar, a runtime and daemons for MPI programs. The below
figure illustrates how the system work and how its performance advantage is
obtained.
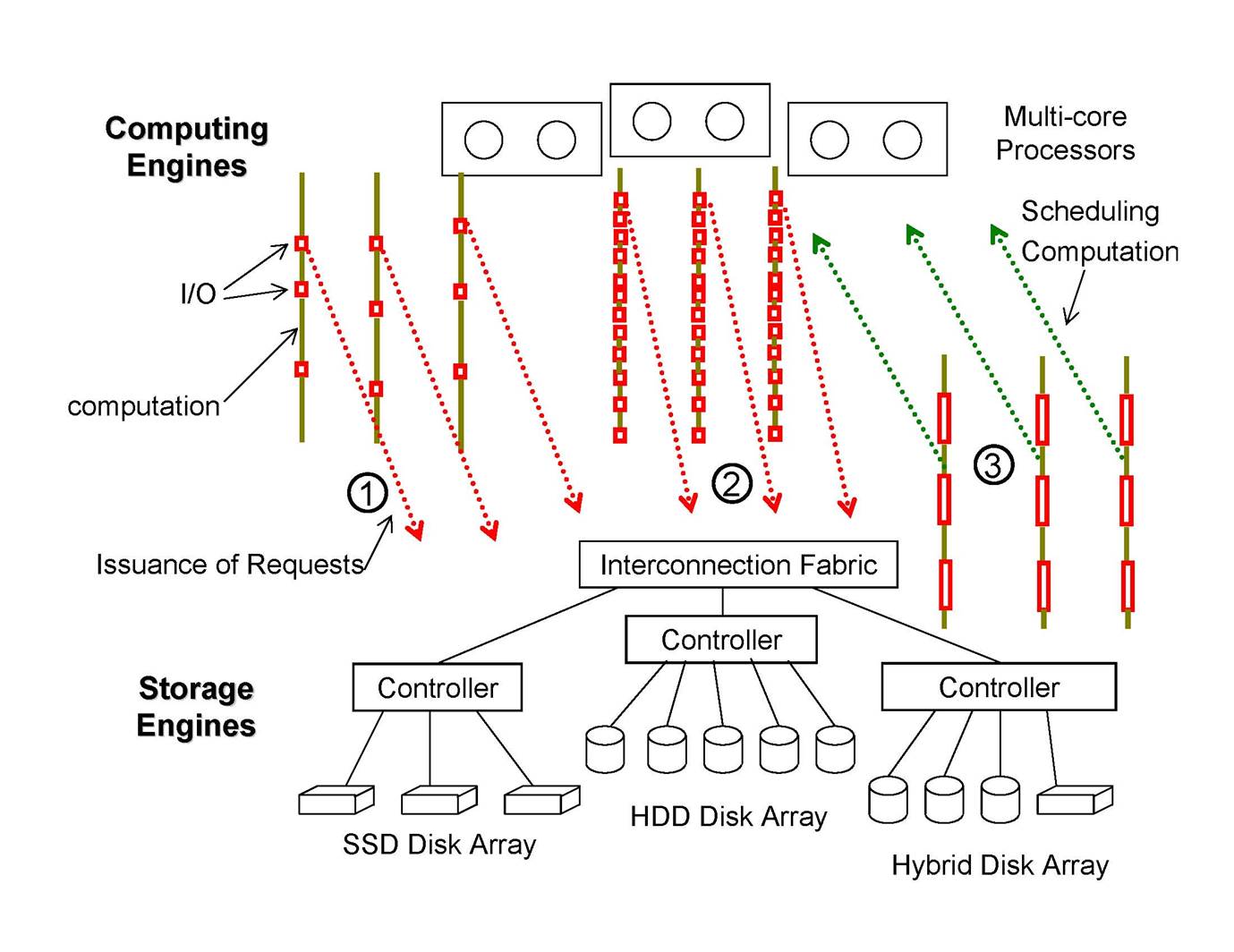
Figure:
Illustration of the concept of a
dual-mode execution. In the figure there are processors (computing engines) and
disk arrays (storage engines) to run three parallel programs. Program 1 is not
I/O intensive (service of I/O requests is denoted as red rectangle). It stays
in the statement-driven execution mode, where the timing of I/O requests is
determined by process scheduling. Program 2 is I/O intensive and is in
statement-driven execution mode. Its requests are issued in the statement
execution order and are served inefficiently. Program 3 is I/O intensive and in
the data-driven mode, where I/O efficiency takes priority in the scheduling of
computation and I/O. I/O requests are served in an order friendly to I/O
efficiency and process scheduling relies on the data availability.
Publications
Related to this Project
v Xiaoning Ding, Jianchen Shan,
Song Jiang. "A
General Approach to Scalable Buffer Pool Management" . In IEEE
Transactions on Parallel and Distributed Systems, 27 (8): August 2016.
v Xingbo Wu, Fan Ni, Li Zhang, Yandong Wang, Yufei Ren,
Michel Hack, Sili Shao, and Song Jiang, "NVMcached:
An NVM-based Key-Value Cache", in Proceedings of the 7th ACM SIGOPS Asia-Pacific Workshop on
Systems (APSys'16), Hong Kong, China, August, 2016.
v Guoyao Xu, Cheng-Zhong Xu,
and Song Jiang, "Prophet:
Scheduling Executors with Time-varying Resource Demands on Data-Parallel
Computation Frameworks", in Proceedings of the 13th IEEE International Conference on
Autonomic Computing (ICAC'16), Wuerzburg,
Germany, July, 2016.
v Xingbo Wu, Li Zhang, Yandong Wang, Yufei Ren, Michel Hack, and Song Jiang, "zExpander:
a Key-value Cache with both High Performance and Fewer Misses", in
Proceedings of the European Conference on Computer Systems (EuroSys'16),
London, UK, April, 2016.
v Xingbo Wu, Wenguang Wang,
and Song Jiang, "TotalCOW:
Unleash the Power of Copy-On-Write for Thin-provisioned Containers", in
Proceedings of the 6th ACM SIGOPS Asia-Pacific Workshop on Systems (APSys2015),
Tokyo, Japan, July, 2015.
v Xingbo Wu, Yuehai Xu, Zili Shao, and Song Jiang, "LSM-trie: An LSM-tree-based Ultra-Large Key-Value Store for
Small Data", in Proceedings of 2015 USENIX Annual Technical Conference
(USENIX'15), Santa Clara, CA, July, 2015.
v Xiameng Hu, Xiaolin Wang, Yechen Li, Lan Zhou, Yingwei Luo, Chen Ding, Song
Jiang, and Zhenlin Wang, "LAMA: Optimized
Locality-aware Memory Allocation for Key-value Cache", in
Proceedings of 2015 USENIX Annual Technical Conference (USENIX'15), Santa
Clara, CA, July, 2015.
v Jianqiang Ou, Marc Patton, Michael Devon Moore, Yuehai Xu,
Song Jiang. A Penalty
Aware Memory Allocation Scheme for Key-value Cache.
In Proceedings of the 44th International Conference on Parallel
Processing (ICPP-2015), Beijing, China, To appear September 2015.
v Yuehai Xu, Eitan Frachtenberg, and Song Jiang, "Building
a High-performance Key-value Cache as an Energy-efficient Appliance", in
Proceedings of the 32st International Symposium on Computer Performance,
Modeling, Measurement and Evaluation 2014 (IFIP Performance 2014),
Turin, Italy, October, 2014.
v
Xuechen Zhang, Jianqiang Ou, Kei Davis,
and Song Jiang, "Orthrus:
A Framework for Implementing Efficient Collective I/O in Multicore Clusters", in Proceedings of
the International Supercomputing Conference (ISC '14), Leipzig, Germany,
June 2014.
v Xuechen Zhang, Ke Liu, Kei Davis, and Song Jiang, "iBridge:
Improving Unaligned Parallel File Access with Solid-State Drives", in Proceedings of
the IEEE International Parallel and Distributed Processing Symposium (IPDPS'13),
Boston, MA, May, 2013.
v Xuechen Zhang, Kei Davis, and Song Jiang, "Opportunistic Data-driven Execution of Parallel Programs for Efficient I/O Services", in Proceedings of the IEEE International Parallel and Distributed Processing Symposium (IPDPS'12), Shanghai, China, May, 2012.
v Yizhe Wang, Kei Davis, Yuehai Xu and Song Jiang, "iHarmonizer:
Improving the Disk Efficiency of I/O-intensive Multithreaded Codes", in Proceedings of
the IEEE International Parallel and Distributed Processing Symposium
(IPDPS'12), Shanghai, China, May, 2012.
Software
v Download Hippos source
code as a Linux loadable kernel module. Hippos 0.01
Hippos is a high-throughput, low-latency,
and energy-efficient key-value store implementation. Hippos moves the KV store
into the operating framework system’s kernel and thus removes most of the
overhead associated with the network stack and system calls. Hippos uses the Netfilter to quickly handle UDP packets, removing the
overhead of UDP-based GET requests almost entirely. Combined with lock-free
multithreaded data access, Hippos removes several performance bottlenecks both
internal and external to the KV-store application.
v Download
LSM-trie source code LSM-trie
1.0
LSM-trie is a KV storage system that substantially reduces metadata for locating KV items, reduces write amplification by an order of magnitude, and needs only two disk accesses with each KV read even when only less than 10% of metadata (Bloom filters) can be held in memory. To this end, LSM-trie constructs a trie, or a prefix tree, that stores data in a hierarchical structure and keeps re-organizing them using a compaction method much more efficient than that adopted for LSM-tree. Our experiments show that LSM-trie can improve write and read throughput of LevelDB, a state-of-the-art KV system, by up to 20 times and up to 10 times, respectively.
REU Program in the project
v Camille
Williams, Michael Moore, and Marc Patton, "Constructing a Distributed
Key Value Cache on a Cluster of Raspberry Pi Computers". (Check out
the  video)
video)
Acknowledgement: