Taming Small Data Writes to Block Storage Devices for
Higher I/O Efficiency
While big data poses a big challenge to storage systems on their capability and efficiency, small data also presents an equally serious threat on their access efficiency. Examples of small data include file system's metadata, lookup table entries in virtual storage devices, and small updates. Almost all storage devices use block interface. When small data (e.g., 128Bytes or less) is substantially smaller than a block (e.g., 4KB), the actual access size would be much larger than the data itself, potentially resulting in wasted device bandwidth and significantly reduced I/O efficiency. Because of demand on immediate data persistency, writes of the small-data continue to be the Achilles' heel of block devices.
There
are multiple software layers in the I/O stack interacting with the block
interface, where small-data writes can inflict performance penalty. The first
layer is the virtual block device, which is hosted on block device(s) to
provide a block interface to virtual machines. For every write of a data block
to a virtual device, the device needs a small write recording where the data
block is stored. The second layer is the I/O scheduler, where requests of block
writes are received and then sent to the (virtual) storage device. Small writes
that can be identified and removed include small update in a data block, a data
block that can be substantially reduced by compression, and a data block that
can be removed by on-line deduplication. The third layer is file system, where
metadata often need to be saved immediately after data write. Servicing these
small writes via block interface is not efficient due to significant write
amplification and often required order between writes of corresponding data
block and metadata.
To
address these challenges raised by small writes, the PI proposes a highly
effective and fundamental approach that is applicable at any layers in an I/O
stack. Instead of relying on any special hardware support or demanding any
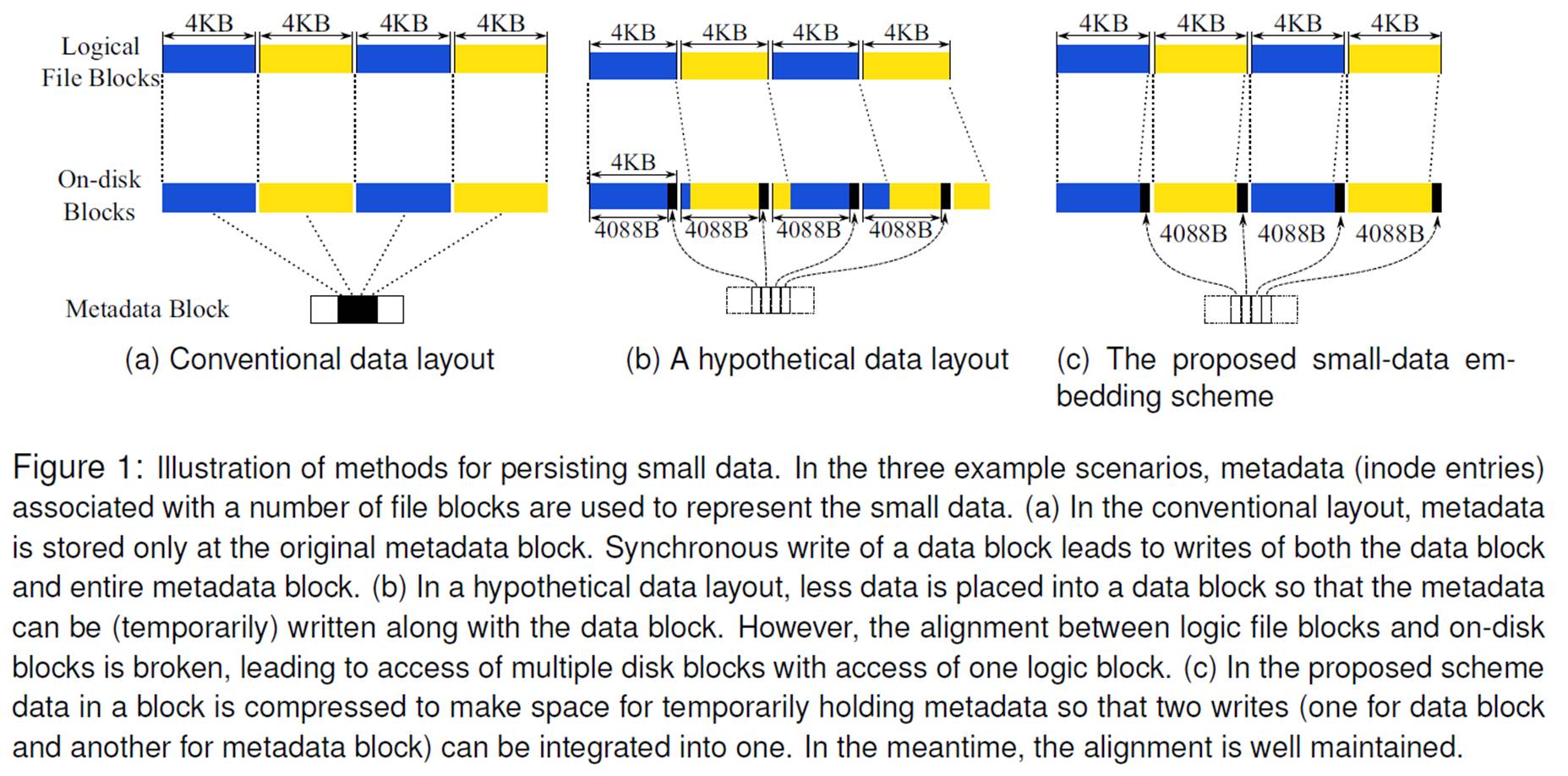
interface changes, this approach leverages data compression technique. As it is
observed that small data usually accompany data blocks, they can be embedded into
the data blocks should the data in the blocks can be compressed. This use of
compression technique represents a deviation from its
conventional employment for reducing data volume, and holds much larger performance advantages. First, because small data are often not contiguous with data blocks, eliminating them not only reduces disk wear (for flash-based SSD) but also removes extra disk seeks (for hard disks). Second, when small data are metadata of a data block and two (or more) writes of them are required to complete a write request of the data block, the writes must follow a certain order to ensure on-disk data consistency. Using flushes to enforce the order would seriously degrade I/O performance. By integrating the metadata and data into one block, which is written in one atomic write, the order issue ca be efficiently addressed.
Software
v Download Wormhole:
A Fast Ordered Index for In-memory Data Management (Wormhole 1.0)
Wormhole is a new ordered index structure that takes O(log L)
worst-case time for looking up a key with a length of L. The low cost is
achieved by simultaneously leveraging strengths of three indexing structures,
namely hash table, prefix tree, and B+ tree, to orchestrate a single fast
ordered index. Wormhole`s range operations can be performed by a linear scan of
a list after an initial lookup. This improvement of access efficiency does not
come at a price of compromised space efficiency. Instead, Wormhole`s index
space is comparable to those of B+ tree and skip list.
v Download WipDB:
A Write-in-place Key-value Store that Mimics Bucket Sort (WipDB 1.0)
WipDB is a KV store design that leverages non-volatile memory and
relatively stable key distributions in the store to bound the write
amplification by a number as low
as 4.15 in practice. The key idea is, instead of incrementally
sorting KV items in the LSM`s hierarchical structure, it writes KV items right
in place in an approximately sorted list, much
like a bucket sort algorithm does. The design also makes it
possible to keep most internal data reorganization operations off the critical
paths of read request service.
v Download
Selfie virtual storage code Selfie 3.3 (also see readme)
Selfie is a virtual disk format,
that eliminates frequent metadata writes by embedding the metadata into data
blocks and making write of a block and its associated metadata be completed in
one atomic block write. This is made possible by opportunistically compressing
the data in a block to make room for the metadata and effectively managing
blocks mixed with metadata and data. In our evaluation Selfie gains as much as
8x performance improvement over existing mainstream virtual disks. It delivers
near-raw performance with an impressive scalability for concurrent I/O
workloads. Selfie can improve write and read throughput of LevelDB, a
state-of-the-art KV system, by up to 20 times and up to 10 times, respectively
v Download
code for WOJ (Write-Once Full-data Journaling) in SSDs WOJ 1.0 (also
see readme)
Leveraging the fact that
with data journal mode all writes to the home locations in a file system are
preceded by corresponding writes to the journal, Write-Once data Journaling (WOJ)
uses a weak-hashing-based deduplication dedicated for removing the second
writes in data journaling within an SSD. WOJ can reduce regular deduplication`s
computation and space overheads significantly without compromising the
correctness. To further reduce metadata persistency cost, WOJ is integrated
with SSD`s
FTL within the device.
The code represents a
prototype of a virtual SSD with WOJ functionality enabled. In the virtual SSD,
the WOJ functionality is implemented in Dmdedup, an open-source deduplication
framework, as a device mapper target at the generic operating system block
device layer in Linux kernel 4.12.4. All the data written to the virtual disk
are first processed in the target and those to be persisted are directed to a
real SSD.
v
Download code for ThinDedup
Deduplication system ThinDedup 1.0 (also
see readme)
ThinDedup compresses the
data and inserts metadata into data blocks to reconcile the incompatibility between
rigid block interface and small metadata. Assuming that performance-critical
data are usually compressible, ThinDedup can mostly remove separate writes of
metadata out of the critical path of servicing users`
requests, and make I/O deduplication much thinner (keeping only data block
writes). In addition to metadata insertion, ThinDedup also uses persistency of
data fingerprints to evade enforcement of write order between data and
metadata. It is implemented in the Linux kernel as a device mapper target to
provide block-level deduplication.
Publications
Related to this Project
- Fan Ni and Song Jiang, "RapidCDC: Leveraging Duplicate Locality to Accelerate
Chunking in CDC-based Deduplication Systems", in
Proceedings of 2019 ACM Symposium on Cloud Computing (ACM SoCC'19),
Santa Cruz, CA, November, 2019.
- Fan Ni, Song Jiang,
Hong Jiang, Xingbo Wu, and Jian Huang, "SDC: A Software Defined Cache Supporting Flexible
Key-value-style Data Caching", in
Proceedings of the 33th ACM International Conference on Supercomputing (ICS'19),
Phoenix, AZ, June, 2019.
- Fan Ni, Xing Lin, and Song Jiang, "SS-CDC: A Two-stage Parallel Content-Defined Chunking
for Deduplicating Backup Storage", in Proceedings of the 12th ACM
International Systems and Storage Conference (SYSTOR'19), Haifa,
Israel, June, 2019.
- Xingbo Wu, Fan Ni, and Song
Jiang, "Wormhole: A Fast Ordered Index for In-memory Data
Management", in Proceedings of the European Conference on
Computer Systems (EuroSys'19), Dresden, Germany, March, 2019.
- Fan Ni, Xingbo Wu, Weijun Li, Lei
Wang, and Song Jiang, "WOJ:
Enabling Write-Once Full-data Journaling in SSDs by Using
Weak-Hashing-based Deduplication",
in Proceedings of the 36th International Symposium on Computer
Performance, Modeling, Measurements and Evaluation (IFIP
Performance 2018), Toulouse, France, December 5-7.
- Fan Ni, Xingbo Wu, Weijun Li, and
Song Jiang, "ThinDedup: An I/O Deduplication
Scheme that Minimizes Efficiency Loss due to Metadata Writes", the 37th
IEEE International Performance Computing and Communications Conference (IPCCC
2018), Orlando, Florida, November 17-19.
- Xingbo Wu, Fan Ni, and Song Jiang,
"Search Lookaside Buffer: Efficient Caching for Index
Data Structures", in Proceedings
of the 2017 ACM Symposium on Cloud Computing (SoCC'17), Santa
Clara, CA, September 2017.
- Fan Guo, Yongkun Li, Yinlong
Xu, Song Jiang, and John C. S. Lui, "SmartMD: A High Performance Deduplication
Engine with Mixed Pages", in Proceedings of 2017 USENIX Annual Technical
Conference (USENIX ATC'17), Santa Clara, CA, July, 2017.
- Yuanyuan Sun, Yu
Hua, Song Jiang, Qiuyu Li, Shunde Cao,
and Pengfei Zuo, "SmartCuckoo: A Fast and Cost-Efficient Hashing Index Scheme
for Cloud Storage Systems", in Proceedings of 2017 USENIX Annual Technical
Conference (USENIX ATC'17), Santa Clara, CA, July, 2017.
- Chunyi Liu, Fan
Ni, Xingbo Wu, Xiao Zhang, and Song Jiang, "Freewrite: Creating (Almost) Zero-Cost Writes to SSD
in Applications",
in Proceedings of the 10th ACM International Systems and Storage
Conference (SYSTOR'17), Haifa, Israel, May, 2017.
- Xingbo Wu, Li
Zhang, Yandong Wang, Yufei Ren, Michel Hack, and Song
Jiang, "zExpander: a Key-value Cache with both High
Performance and Fewer Misses", in Proceedings of the
European Conference on Computer Systems (EuroSys'16), London, UK,
April, 2016.
- Xingbo Wu, Zili Shao, and Song
Jiang, "Selfie: Co-locating Metadata and Data to Enable Fast
Virtual Block Devices", In Proceedings
of the 10th ACM International Systems and Storage
Conference (SYSTOR2015), Haifa,
Israel, May 2015.
Participants

- Song Jiang (PI)
- Xingbo Wu (Ph.D. student)
- Fan
Ni (Ph.D. Student)
- Xinsheng
Zhao (Ph.D. Student)
- David Chavez (Undergraduate)
- Ibukunoluwa Aboderin (Undergraduate)
- Guerrero
Vester Diego
- Luis Martinez
- Michael
Jezreel Aquitania
- Tolulope
Miracle Omoloja,
REU Program on the project
(see the REU website and
a Student Presentation)
- David
Chavez, "Opportunistic Value Separation for Reduced Compaction
Cost and Optimized Read Performance in LevelDB", Summer, 2017.
- Ibukunoluwa
Aboderin, "Optimization of Array-based Key-Value Store",
Summer, 2017.
- Research
Training for Undergraduate Students at UTA in 2018
Acknowledgements:
- NSF, "Taming
Small Data Writes to Block Storage Devices for Higher I/O Efficiency", 2015 - 2019.
- STARS
Program from University of Texas System for acquisition of computing
equipment.
- Facebook,
Inc. Donation of Twelve servers (Intel 8-core Xeon and 64GB DRAM) and
traces from Memcached production platforms.